|
I am a Ph.D. student in Computer Science at Stanford University and part of the Stanford Artificial Intelligence Laboratory (SAIL). I am interested in the capability of robots and other agents to develop broadly intelligent behavior through learning and interaction. My reserach is focused on a data-driven approach to embodied AI, which aims to re-use previously collected data to deploy in offline reinforcement, planning and imitation learing, particularly in realistic domains. I am also interested in model-based learning, generative modelling and real-world deployment of RL. Previously I obtained Masters degrees in Statistics and Computer Science (with distinction in research) also at Stanford. Before that, I graduated from UC Berkeley with highest honors in Applied Mathematics, Statistics and Economics. Before graduate school I was a junior portfolio manager at Goldman Sachs' Quantitative Investment Startegies (QIS) unit. |

|
|
|
My research interests lie at the intersection of machine learning, perception, and control for robotics, specifically deep reinforcement learning, imitation learning and meta-learning. |
|
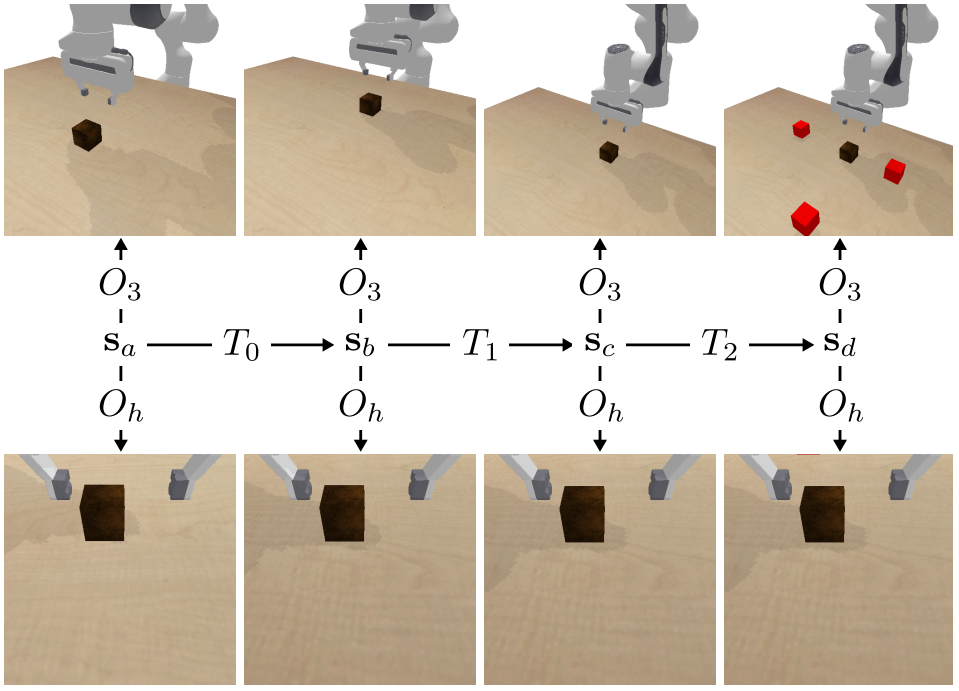
A hand-centric (eye-in-hand) perspective consistently improves training efficiency and out-of-distribution generalization in robotic manipulation. These benefits hold across a variety of learning algorithms, experimental settings, and distribution shifts. When hand-centric observability is not sufficient, including a third-person perspective is necessary for learning, but also harms out-of-distribution generalization. To mitigate this, we propose to regularize the third-person information stream via a variational information bottleneck. |
|
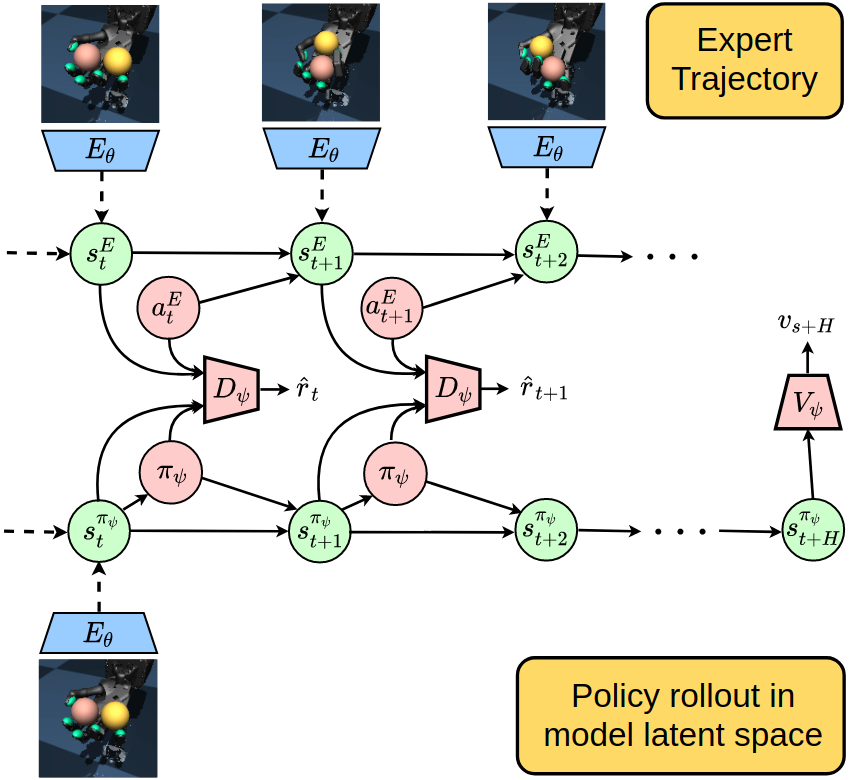
We develop a variational model-based adversarial imitation learning (V-MAIL) algorithm. We train a low-dimensional variational dynamics model from high-dimensional image observtions, which provides a strong signal for representation learning. We then use on-policy model-generated data to train an adversarial imitation learning agent which improves sample efficiency and stability of adversarial training. We can also transfer the learned model to new imitation tasks, enabling zero-shot adversarial imitation learning. |
|
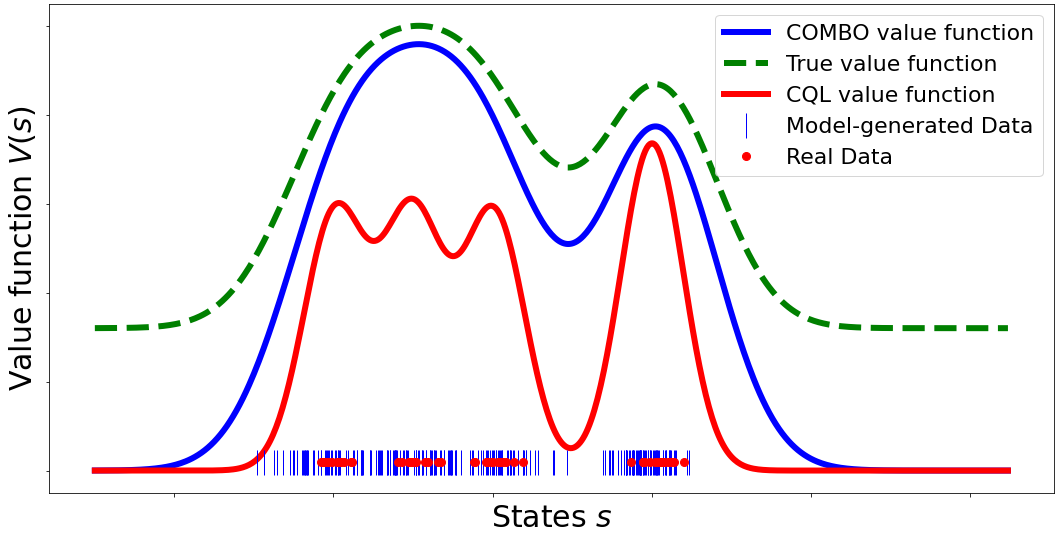
Model-based offline RL methods rely on explicit uncertainty quantification for incorporating pessimism, which can be difficult and unreliable with complex models. We overcome this limitation by developing a new model-based offline RL algorithm, COMBO, that regularizes the value function on out-of-support state-action tuples generated via rollouts under the learned model. We show COMBO with theoretical guarantees and also find that COMBO consistently performs as well or better as compared to prior offline model-free and model-based methods on widely studied offline RL benchmarks, including image-based tasks. |
|
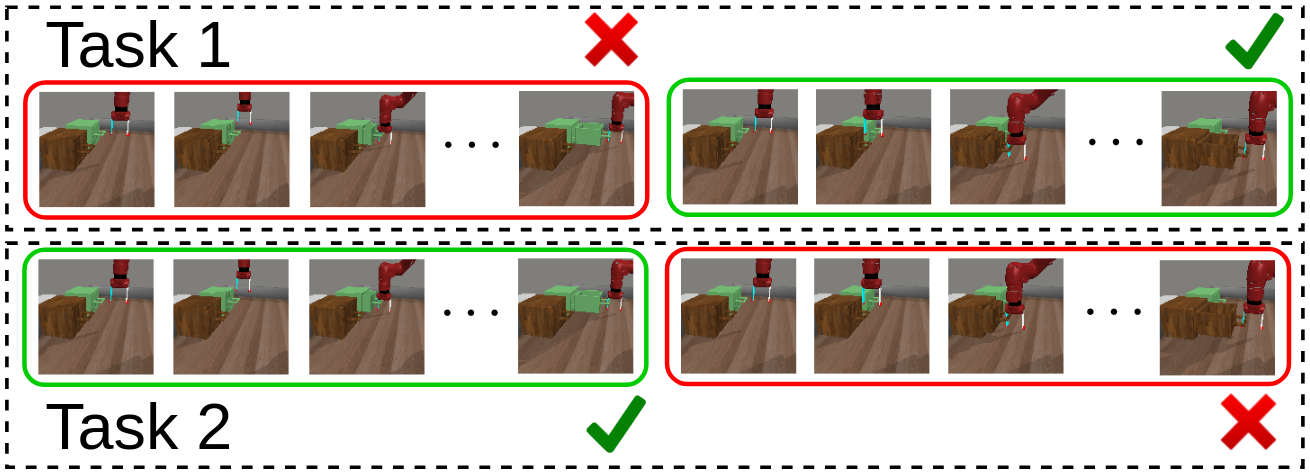
In this work we develop an offline model-based meta-RL algorithm that operates from images in tasks with sparse rewards. Our approach has three main components: a novel strategy to construct meta-exploration trajectories from offline data, which allows agents to learn meaningful meta-test time task inference strategy; representation learning via variational filtering and latent conservative model-free policy optimization. We show that our method completely solves a realistic meta-learning task involving robot manipulation, while naive combinations of previous approaches fail. |
|
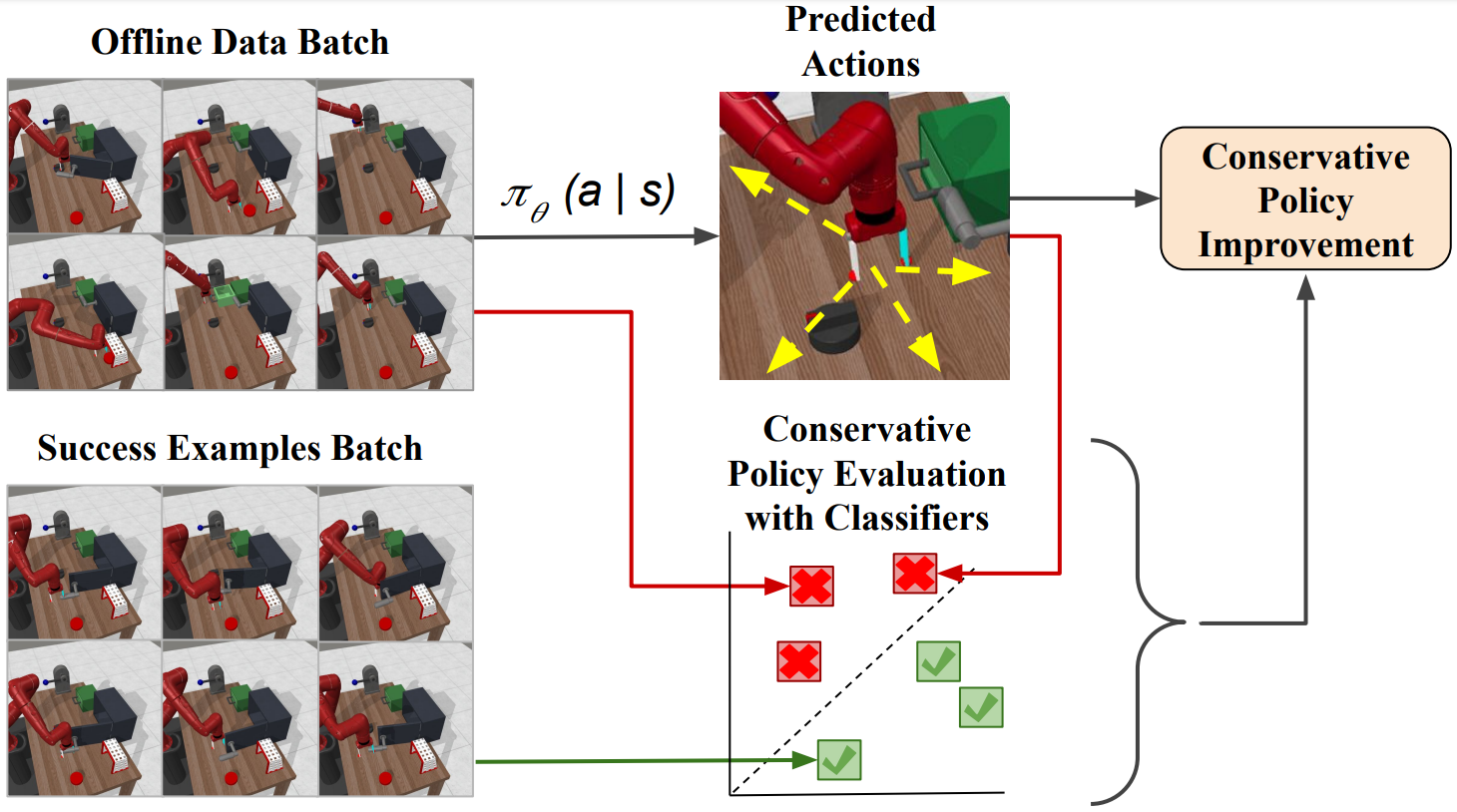
Offline RL methods require human-defined reward labels to learn from offline datasets. Reward specification remains a major challenge for deep RL algorithms in the real world since designing reward functions could take considerable manual effort. In contrast, in many settings, it is easier for users to provide examples of a completed task such as images than specifying a complex reward function. Based on this observation, we propose an algorithm that can learn behaviors from offline datasets without reward labels, instead using a small number of example images. |
|
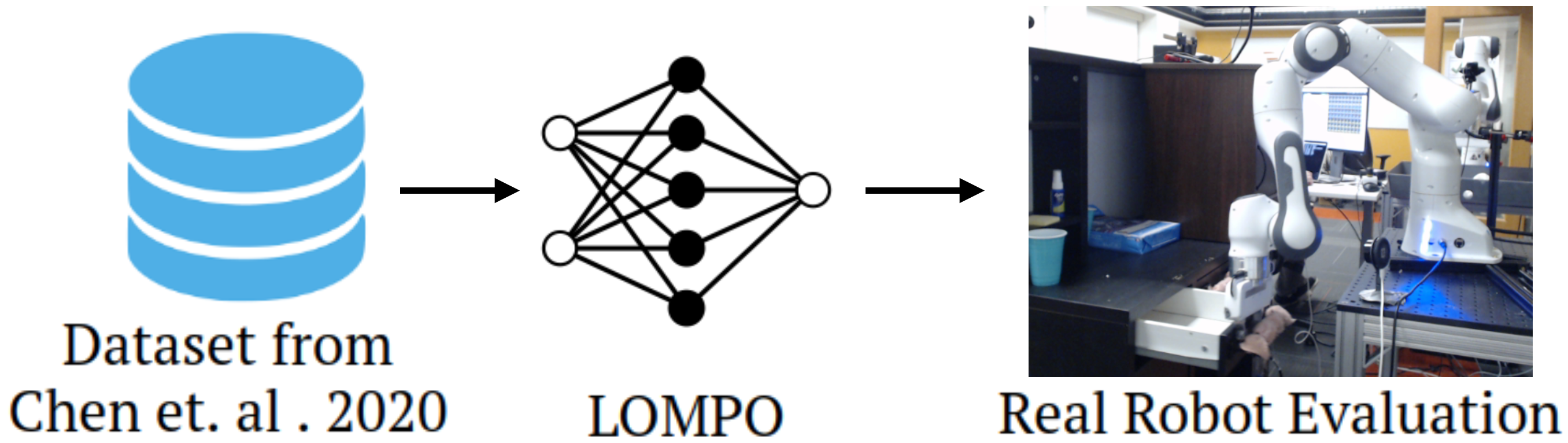
Model-based offline RL algorithms have achieved state of the art results in state based tasks and have strong theoretical guarantees. However, they rely crucially on the ability to quantify uncertainty in the model predictions, which is particularly challenging with image observations. To overcome this challenge, we propose to learn a latent-state dynamics model, and represent the uncertainty in the latent space. We find that our algorithm significantly outperforms previous offline model-free RL methods as well as state-of-the-art online visual model-based RL methods in both simulated and real-world robotics control tasks. |
|
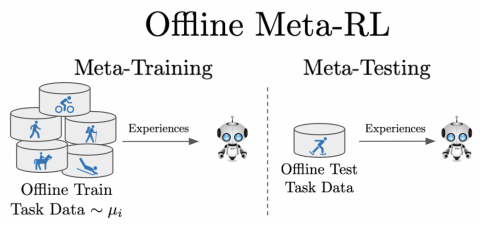
Offline meta-RL is analogous to the widely successful supervised learning strategy of pre-training a model on a large batch of fixed, pre-collected data (possibly from various tasks) and fine-tuning the model to a new task with relatively little data. By nature of being offline, algorithms for offline meta-RL can utilize the largest possible pool of training data available and eliminate potentially unsafe or costly data collection during meta-training. This setting inherits the challenges of offline RL, but it differs significantly because offline RL does not generally consider a) transfer to new tasks or b) limited data from the test task, both of which we face in offline meta-RL. Targeting the offline meta-RL setting, we propose Meta-Actor Critic with Advantage Weighting (MACAW), an optimization-based meta-learning algorithm that uses simple, supervised regression objectives for both the inner and outer loop of meta-training. |
|
|
|
|